

Wie man mithilfe von KI Daten aus PDF-Dateien extrahiert
Künstliche Intelligenz (KI) hat die moderne Geschäftswelt revolutioniert. Sie verändert die Art und Weise, wie Unternehmen arbeiten, Entscheidungen treffen und mit Kunden interagieren. Ein Bereich, in dem KI besonders bemerkenswerte Fortschritte gemacht hat, ist die Automatisierung der Datenextraktion aus PDFs.
Obwohl PDFs in der Geschäftswelt weit verbreitet sind, stellt das Extrahieren von Daten aus ihnen häufig eine Herausforderung dar. Warum? Der Grund liegt in ihrer Struktur. PDFs sind so gestaltet, dass sie für Menschen lesbar sind – nicht für Maschinen. Dies macht die manuelle Bearbeitung von Daten zeitaufwändig und monoton. Mit KI ist es jedoch möglich, diesen Prozess vollständig zu automatisieren, wodurch Unternehmen wertvolle Zeit und Ressourcen sparen können.
Wie extrahiert man Daten aus PDFs mithilfe von KI?
Seien wir ehrlich. Wenn Sie nur wenige PDF-Dokumente haben, aus denen Sie Daten extrahieren müssen, ist die manuelle Methode des Kopierens und Einfügens möglicherweise ausreichend. Der Prozess ist simpel: Öffnen Sie jedes Dokument, markieren Sie die benötigten Daten und kopieren Sie sie an den gewünschten Ort. Doch was passiert, wenn Sie hunderte oder tausende PDFs bearbeiten müssen? Manuelles Extrahieren wird schnell ineffizient und fehleranfällig.
Hier kommt KI ins Spiel. KI-Tools zur automatisierten Datenextraktion können große Mengen von PDF-Dokumenten in kürzester Zeit verarbeiten, die Informationen validieren und verifizieren und sie direkt an den gewünschten Speicherort übertragen.
So funktioniert die Datenextraktion aus PDFs mit KI:
- Hochladen des Dokuments: Der erste Schritt besteht darin, das PDF-Dokument in das KI-Tool hochzuladen. Dies können unterschiedlichste Dokumente sein, wie Rechnungen, Kundenaufträge oder Verträge. Das Tool analysiert das Dokument und identifiziert automatisch die Bereiche, die relevante Daten enthalten.
- Datenextraktion: Sobald die relevanten Bereiche identifiziert wurden, verwendet das KI-Tool fortschrittliche Algorithmen und große Sprachmodelle (LLMs), um die Daten präzise zu extrahieren. Dazu können Informationen wie Rechnungsnummern, Kundennamen, Bestelldetails oder Zahlungsinformationen gehören.
- Überprüfung und Validierung der Daten: Nach der Extraktion werden die Daten automatisch überprüft und validiert, um ihre Richtigkeit sicherzustellen. Das KI-gestützte System gleicht die Daten mit vorgegebenen Regeln, Mustern oder Referenzdaten ab, um Fehler oder Inkonsistenzen zu vermeiden.
- Übertragung der Daten: Abschließend werden die validierten Daten automatisch an den gewünschten Speicherort, wie ein ERP- oder CRM-System, übertragen. Alternativ können die Daten vor der Übertragung manuell geprüft werden, falls zusätzliche Kontrolle erforderlich ist.
Wie funktioniert KI bei der PDF-Datenextraktion?
Die KI-basierte Datenextraktion, auch als intelligente Datenerfassung bekannt, nutzt KI-, LLM- und NLP-Techniken, um relevante Informationen aus einer PDF-Datei zu extrahieren – unabhängig von deren Struktur oder Layout.
Hier ist ein vereinfachter Prozessablauf, der zeigt, wie KI-gestützte Lösungen Daten aus PDF-Dokumenten extrahieren:

1. Datenerfassung
Dieser Schritt bildet die Grundlage des gesamten Prozesses. Die KI beginnt mit der Aufnahme unstrukturierter Daten aus verschiedenen Quellen wie gescannten Dokumenten, E-Mails, PDFs, Bildern oder digitalen Dateien.
2. Vorverarbeitung
Nach der Datenerfassung folgt die Vorverarbeitung. Dabei werden Aufgaben wie Rauschunterdrückung, Bildverbesserung oder Textumwandlung durchgeführt, um die Lesbarkeit und Qualität der Daten zu verbessern. Besonders wichtig ist dabei der Einsatz von OCR (Optical Character Recognition), das Bilder, gescannte Dokumente oder handschriftlichen Text in maschinenlesbaren Text umwandelt.
3. Datenextraktion
Nach der Vorverarbeitung nutzt das KI-System Techniken wie LLMs und NLP, um die relevanten Informationen im Dokument zu identifizieren und zu extrahieren. Dies umfasst die Erkennung von Schlüsselfeldern wie Namen, Adressen, Daten oder Rechnungsnummern sowie die strukturierte Extraktion der benötigten Daten.
4. Datenvalidierung und -verifizierung
Die KI validiert und überprüft die extrahierten Daten, um deren Genauigkeit sicherzustellen. Dies geschieht durch Abgleich mit bestehenden Datenbanken, Validierungsprüfungen oder vordefinierten Regeln. Zum Beispiel erkennt das KI-System fehlende Informationen wie eine Rechnungsnummer oder ein Datum, markiert den Fehler und benachrichtigt das zuständige Team, damit er behoben wird.
5. Datenintegration:
Sobald die Daten extrahiert, verifiziert und validiert wurden, besteht der letzte Schritt darin, sie in Ihr System oder Ihre Datenbank einzugeben. KI-gestützte Lösungen können nahtlos in bestehende Systeme wie CRMs oder ERPs integriert werden, wodurch die manuelle Dateneingabe überflüssig wird und das Fehlerrisiko reduziert wird. Dies bedeutet, dass Unternehmen über genaue, aktuelle und fehlerfreie Daten verfügen, um fundierte Entscheidungen zu treffen.
Technologien zur Datenextraktion aus PDF-Dateien
Nachdem Sie nun eine Vorstellung davon haben, wie KI bei der Datenextraktion aus PDFs funktioniert, werfen wir einen Blick auf die Schlüsseltechnologien, die diesen Lösungen zugrunde liegen:
Optische Zeichenerkennung (OCR)
Die optische Zeichenerkennung (OCR) ist eine der am häufigsten verwendeten Technologien zur Datenextraktion aus PDFs. OCR-basierte Tools können Daten effektiv aus strukturierten PDF-Dokumenten mit vorhersehbarem Layout extrahieren.
Allerdings stößt OCR bei Dokumenten mit variierenden Layouts oder komplexen Strukturen an ihre Grenzen, da es auf der Identifikation von Daten anhand ihrer festen Positionen im Dokument basiert. Sobald sich das Layout eines Dokuments ändert, müssen die OCR-Einstellungen manuell angepasst werden. Dies macht den Prozess weniger flexibel und zeitraubend, insbesondere bei der Verarbeitung großer Datenmengen.
Verarbeitung natürlicher Sprache (NLP)
Die Verarbeitung natürlicher Sprache (NLP) wird ebenfalls häufig für die Datenextraktion aus PDFs eingesetzt. NLP-Techniken sind besonders nützlich, um Text aus Dokumenten mit konsistenten Strukturen zu extrahieren. Allerdings geraten auch diese Methoden bei großen, komplexen Datenmengen an ihre Grenzen.
Trotzdem bietet NLP eine wertvolle Unterstützung, um den extrahierten Text zu bereinigen. So können NLP-Modelle beispielsweise Rauschen, unerwünschte Symbole oder fehlerhafte Zeichen aus den Daten herausfiltern, die während des Kodierungsprozesses in das Dokument gelangt sind. Das Ergebnis sind sauberere und genauere Daten.
KI-basierte Lösungen
KI-basierte Ansätze stellen die modernste und effizienteste Methode zur Datenextraktion aus PDFs dar. Anders als OCR oder regelbasierte Techniken können KI-gestützte Systeme den Kontext und die Bedeutung von Daten im Dokument verstehen. Dadurch sind sie in der Lage, Daten unabhängig von der Struktur oder dem Layout präzise zu extrahieren.
Darüber hinaus können KI-gestützte Lösungen nicht nur maschinengeschriebenen Text verarbeiten, sondern auch Daten aus handschriftlichen Notizen oder Bildern in einer PDF-Datei extrahieren. Dies ist besonders vorteilhaft für Unternehmen, die mit einer Vielzahl unterschiedlicher Dokumenttypen arbeiten, wie beispielsweise Rechnungen, Kundenaufträgen, Verträgen oder Bestellungen.
Die Herausforderungen beim Extrahieren von Daten aus PDFs

Bildnachweis: Ideagram
Das Portable Document Format (PDF) ist ein zweischneidiges Schwert für Unternehmen. Einerseits bietet es enorme Flexibilität, wenn es darum geht, Informationen zu speichern und weiterzugeben. PDFs können auf nahezu jedem Gerät geöffnet und angezeigt werden, unabhängig von der verwendeten Software. Außerdem erlauben PDFs eine individuelle Datenorganisation ohne feste Struktur- oder Schemaregeln, was sie in der Geschäftswelt allgegenwärtig macht.
Diese Flexibilität birgt jedoch Herausforderungen, insbesondere bei der Datenextraktion. Hier sind einige der häufigsten Probleme, mit denen Unternehmen konfrontiert sind:
1. Inkonsistentes Layout und Formatierung
PDFs weisen oft ein uneinheitliches Layout auf, was die programmgesteuerte Datenextraktion erschwert. Texte, Tabellen oder Bilder können so formatiert sein, dass ihre ursprüngliche Bedeutung oder Struktur nicht beibehalten wird. Beispielsweise kann ein mehrspaltiges Layout oder ein nichtlinearer Textfluss die Extraktionstools verwirren und zu unvollständigen oder falschen Daten führen.
Darüber hinaus können Informationen in verschiedenen PDFs derselben Quelle unterschiedlich dargestellt werden. Ein bestimmtes Datenfeld könnte in einem Dokument fett gedruckt und unterstrichen sein, während es in einem anderen kursiv oder farblich hervorgehoben wird. Diese Uneinheitlichkeit erschwert die automatische Extraktion und führt oft zu Fehlern, die manuell korrigiert werden müssen.
2. Datenqualität und -typen
Die Qualität gescannter PDFs hat einen erheblichen Einfluss auf die Datenextraktion. Schlechte Scans können OCR-Fehler, fehlende Informationen oder fehlerhafte Datenextraktion verursachen, was Unternehmen zwingt, aufwendige Korrekturen vorzunehmen oder fortschrittliche Algorithmen zur Fehlerbehebung einzusetzen.
Zudem enthalten PDFs häufig eine Mischung aus verschiedenen Datentypen, wie Text, Bilder, Tabellen, Diagramme und sogar Multimedia-Elemente. Die Extraktion von Daten aus solch unterschiedlichen Inhalten erfordert verschiedene Strategien und Technologien, was den gesamten Prozess zusätzlich verkompliziert.
3. Sicherheitsfunktionen und verschlüsselte Dateien
Viele PDFs sind mit Sicherheitsfunktionen ausgestattet, die das Kopieren, Bearbeiten oder Drucken einschränken. In einigen Fällen enthalten sie verschlüsselte Daten, die vor der Extraktion entschlüsselt werden müssen. Um mit solchen Dokumenten zu arbeiten, müssen Unternehmen entweder entsprechende Berechtigungen einholen oder Technologien einsetzen, die diese Sicherheitsmaßnahmen umgehen können.


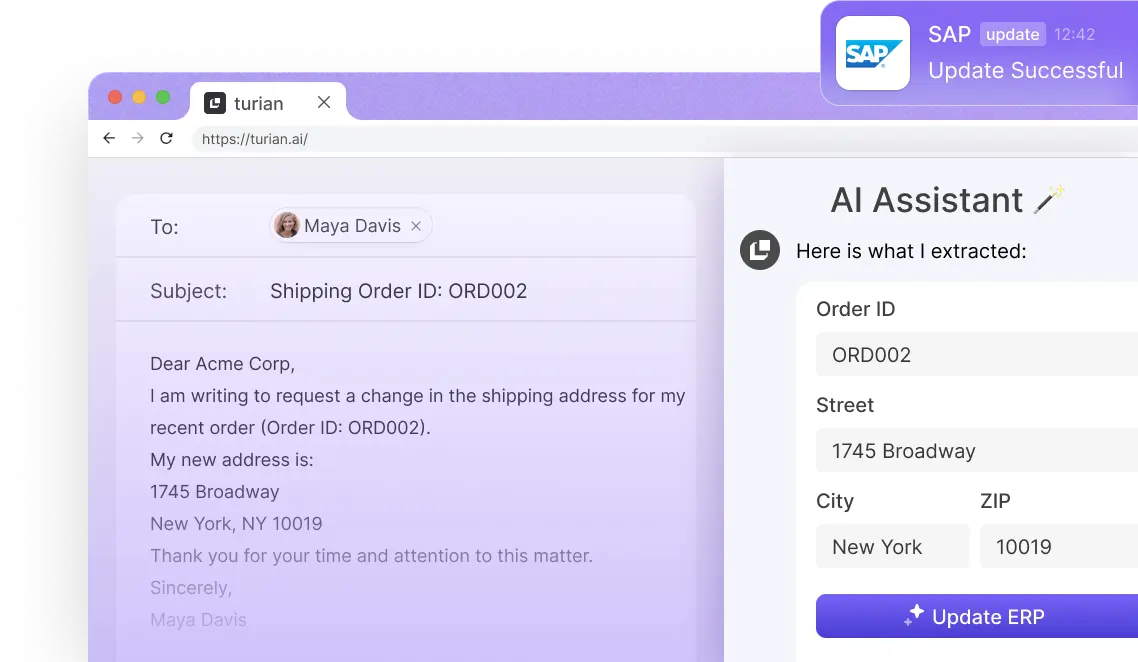
Ein häufiges Beispiel für die Herausforderungen der PDF-Datenextraktion sind gescannte Dokumente mit handschriftlichen Notizen, wie eine Auftragsbestätigung mit Änderungen des Lieferdatums. Solche Dokumente sind für Menschen leicht verständlich, jedoch für Maschinen äußerst komplex.Mit seinen fortschrittlichen Funktionen konnte turian AI in einem solchen Beispiel das Lieferdatum korrekt als 08.02.2024 identifizieren, obwohl es handschriftlich in einem anderen Format als der Rest des Textes geschrieben war. Dies zeigt, wie leistungsstark KI-gestützte Lösungen wie turian sind, wenn es darum geht, Daten aus komplexen und unstrukturierten PDFs zu extrahieren.
Die Vorteile des Einsatzes von KI für die PDF-Datenextraktion

Bildnachweis: DilokaStudio
KI-gestützte Lösungen revolutionieren die Art und Weise, wie Unternehmen Daten aus PDF-Dokumenten extrahieren. Im Gegensatz zur manuellen Datenextraktion, bei der jedes Dokument zeilenweise gelesen und die erforderlichen Daten manuell extrahiert, überprüft und in das System eingegeben werden müssen, automatisieren KI-Tools den gesamten Prozess von Anfang bis Ende.
Hier sind einige der wichtigsten Vorteile, die Unternehmen durch den Einsatz von KI für die Datenextraktion aus PDFs genießen können:

1. Schnelle und effiziente Datenextraktion
Einer der größten Vorteile von KI-gestützten PDF-Datenextraktionstools ist ihre Geschwindigkeit und Effizienz. Während die manuelle Verarbeitung großer Mengen von PDF-Dokumenten Stunden oder sogar Tage in Anspruch nehmen kann, erledigen KI-Lösungen diese Aufgabe in wenigen Minuten. Dies spart nicht nur wertvolle Zeit, sondern erhöht auch die Produktivität Ihres Teams, das sich auf strategischere Aufgaben konzentrieren kann.
2. Genauere und zuverlässigere Daten
Manuelle Prozesse sind anfällig für menschliche Fehler, die von einfachen Tippfehlern bis zum Übersehen wichtiger Informationen reichen können. Dies wirkt sich negativ auf die Datenqualität und -integrität aus, was wiederum die Entscheidungsfindung behindern kann. KI-gestützte Lösungen eliminieren die manuelle Dateneingabe und damit auch die damit verbundenen Fehler.
Das bedeutet:

- Keine doppelten Einträge oder fehlenden Informationen
- Keine zeitaufwendigen Korrekturen fehlerhafter Daten
- Höhere Datenqualität und zuverlässigere Entscheidungsgrundlagen
3. Anpassungsfähigkeit an verschiedene Dokumenttypen
KI-Lösungen sind flexibel und anpassungsfähig, sodass sie mit verschiedenen Dokumentenlayouts, -formaten und -strukturen umgehen können. Egal, ob Ihre PDF-Dateien Tabellen, Diagramme, Bilder oder textbasierte Inhalte enthalten – KI-Tools können die relevanten Daten präzise extrahieren. Diese Vielseitigkeit macht KI ideal für Unternehmen, die mit einer Vielzahl unterschiedlich strukturierter PDF-Dokumente arbeiten.
4. Kosteneffiziente Lösung
Durch die Automatisierung der Datenextraktion können Unternehmen erhebliche Kosten einsparen, die mit manueller Arbeit und durch Fehler verursachten Nacharbeiten verbunden sind. Nach der einmaligen Implementierung senken KI-Lösungen die Betriebskosten erheblich und bieten gleichzeitig eine skalierbare Lösung, die auch bei wachsendem Dokumentenvolumen keine zusätzlichen Ressourcen erfordert.
Abgesehen von den Hauptvorteilen bieten KI-gestützte Lösungen weitere Funktionen, die sie zu einer wertvollen Investition machen. Sie verbessern die Datensicherheit, indem sie sensible Informationen während der Verarbeitung schützen und somit die Integrität und Vertraulichkeit der Daten gewährleisten. Zudem lassen sie sich nahtlos in bestehende Systeme wie CRMs und ERPs integrieren, was eine effiziente und störungsfreie Einbindung in die bestehenden Arbeitsabläufe ermöglicht. Ein weiterer Vorteil ist die Fähigkeit zur mehrsprachigen Datenverarbeitung. KI kann Daten in verschiedenen Sprachen extrahieren und analysieren, was besonders für global agierende Unternehmen von großem Nutzen ist, die mit Dokumenten aus unterschiedlichen Sprachräumen arbeiten.
Datenextraktion aus PDFs mit turian optimieren und automatisieren:
Wenn Sie eine effizientere, zuverlässigere und intelligentere Methode zur Datenextraktion aus PDF-Dokumenten suchen, ist turian die ideale Lösung. Unsere Technologie basiert auf modernster KI, einschließlich großer Sprachmodelle (LLMs), maßgeschneiderter Geschäftsregeln und fortschrittlicher Datenabfragetechniken, um präzise und nahtlose Datenextraktion aus allen Arten von PDF-Dokumenten zu ermöglichen. Egal ob Rechnungen, Kundenaufträge, Verträge oder andere Dokumenttypen – unabhängig von Layout, Sprache oder Komplexität bewältigt unsere KI-Lösung jede Herausforderung.
turian ist jedoch nicht auf PDFs beschränkt. Unsere KI-gestützte Technologie kann auch Daten aus verschiedenen Dokumentformaten extrahieren, darunter E-Mails, Excel-Tabellen, Word-Dokumente, Bilder und sogar handschriftliche Notizen. Dabei extrahiert turian nicht nur die Daten, sondern versteht auch deren Kontext und Bedeutung. Die Lösung gleicht die extrahierten Informationen mit den bereits in Ihrem System vorhandenen Daten ab und liefert konsistente, fehlerfreie Ergebnisse.
Sollten Unstimmigkeiten oder Fehler auftreten, wie etwa Tippfehler oder fehlende Angaben, markiert turian diese für die manuelle Überprüfung. So sparen Sie wertvolle Zeit und reduzieren den Aufwand für die Datenprüfung. Wenn beispielsweise eine Rechnung eine falsche Bestellnummer oder einen fehlenden Preis enthält, erkennt turian das Problem, hebt es hervor und leitet es an einen Prüfer weiter, bevor die Daten in Ihr System übertragen werden. Auf diese Weise wird die Genauigkeit und Konsistenz Ihrer Daten gewährleistet, ohne dass umfangreiche manuelle Eingriffe erforderlich sind.
Darüber hinaus ist turian in der Lage, komplexe Aufgaben zu bewältigen, die ein menschenähnliches Verständnis und Entscheidungsfindung erfordern. Beispiele hierfür sind das Verfassen von E-Mail-Antworten oder die Analyse von Kundenfeedback. Im Gegensatz zu herkömmlichen OCR-Tools benötigt turian keine manuelle Anpassung oder Schulung. Es passt sich an jede Dokumentenstruktur oder jedes Layout in jeder Sprache an und bietet damit eine universelle und skalierbare Lösung.
turian kann nahtlos in bestehende ERP-/CRM-Systeme sowie gängige E-Mail-Plattformen wie Outlook oder Gmail integriert werden, um Ihre Arbeitsabläufe zu optimieren. Zusätzlich ist turian eine No-Code-Lösung, was bedeutet, dass keine technischen Vorkenntnisse oder aufwendige Schulungen erforderlich sind, um es in Ihren Geschäftsprozessen einzusetzen.
Wenn Sie testen möchten, wie turian Ihre Datenextraktion aus PDFs automatisieren und Ihre Geschäftsprozesse optimieren kann, bieten wir Ihnen die Möglichkeit eines kostenlosen Proof of Concept (PoC). Mit dieser Testphase können Sie direkt erleben, wie turian Ihre spezifischen Anforderungen erfüllt und Ihnen hilft, Zeit und Ressourcen zu sparen.
{{de-cta-block-blog}}

Say hi to your
AI Assistant!
Lernen Sie Ihren KI-Assistenten kennen!
.avif)
FAQ
Die KI-basierte PDF-Datenextraktion ist ein automatisierter Prozess, bei dem Techniken der künstlichen Intelligenz (KI) wie Large Language Models (LLMs) und Natural Language Processing (NLP) eingesetzt werden, um Daten aus PDF-Dokumenten zu erfassen, zu extrahieren und zu validieren. Lösungen wie turian ermöglichen es, Daten aus verschiedenen Arten von PDFs – darunter Rechnungen, Bestellungen und Kundenaufträge – mit hoher Präzision und Effizienz zu verarbeiten. Dadurch wird die manuelle Dateneingabe überflüssig, und der gesamte Extraktionsprozess wird automatisiert.
Die optische Zeichenerkennung (OCR) ist eine Technologie, die Text aus gescannten Dokumenten oder Bildern in maschinenlesbare Formate umwandelt. OCR-basierte Lösungen funktionieren besonders gut, wenn die Dokumentenstruktur vorhersehbar ist und der Text klar formatiert vorliegt. Wenn jedoch Dokumente eine komplexe oder uneinheitliche Struktur aufweisen, kann OCR Schwierigkeiten haben, die Daten präzise zu extrahieren. Dies liegt daran, dass OCR auf festen Koordinaten innerhalb des Dokuments basiert, was bei variierenden Layouts zu Fehlern führt.
Im Gegensatz dazu verwendet die KI-basierte PDF-Datenextraktion fortschrittliche Techniken wie LLMs und NLP, um Texte zu analysieren und Daten auf Grundlage von Kontext, Sprachmustern und den Beziehungen zwischen Wörtern zu extrahieren. Dadurch können KI-gestützte Tools auch unstrukturierte oder komplexe Dokumente effektiv verarbeiten und bieten eine deutlich höhere Genauigkeit als OCR-basierte Methoden.
Ja, turian wurde entwickelt, um Daten aus nahezu jeder Art von Dokument zu extrahieren, nicht nur aus PDFs. Die Lösung kann auch Informationen aus gescannten Dokumenten, Bildern, E-Mails, Word-Dateien, Excel-Tabellen und sogar handschriftlichen Notizen präzise extrahieren. Unabhängig von der Komplexität der Dokumentenstruktur, dem Format oder der Sprache bietet turian eine zuverlässige Datenextraktion, die sich nahtlos in verschiedene Geschäftsprozesse integrieren lässt.



