

Vollständiger Leitfaden zur Datenextraktion aus Dokumenten
In der heutigen digitalen Welt sind Daten allgegenwärtig. Doch es geht nicht nur darum, Daten zu besitzen, sondern darum, sie effektiv zu nutzen, um Ihr Unternehmen voranzubringen. Wenn Daten extrahiert, organisiert und verarbeitet werden, sodass sie zugänglich und nutzbar sind, verwandeln sie sich in ein leistungsstarkes Werkzeug, das fundierte Entscheidungen erleichtert, Wachstum fördert und Ihr Unternehmen von der Konkurrenz abhebt.
Wer jedoch schon einmal Stunden damit verbracht hat, Informationen manuell aus verschiedenen Dokumenten wie Rechnungen, Bestellungen oder Verträgen zu extrahieren, weiß, wie mühsam und ineffizient dieser Prozess sein kann. Die manuelle Datenextraktion erfordert nicht nur Präzision und Detailgenauigkeit, sondern ist auch extrem zeitaufwendig.
Manuelle Methoden bringen nicht nur Langeweile und einen hohen Zeitaufwand mit sich, sondern auch die Gefahr von Fehlern und Inkonsistenzen. Je mehr Dokumente bearbeitet werden müssen, desto schwieriger wird es, die Aufgabe zuverlässig zu bewältigen. Mit der zunehmenden Verfügbarkeit von KI-Technologien ist die Datenextraktion aus Dokumenten jedoch einfacher, schneller und effizienter geworden.
Automatisierte Lösungen zur Dokumentdatenextraktion übernehmen die Arbeit für Sie. Sie extrahieren Informationen aus einer Vielzahl von Dokumenten wie PDFs, gescannten Bildern oder digitalen Formaten und wandeln diese in strukturierte Daten (z. B. XML, CSV, XLS) um. Diese Daten können nahtlos in bestehende Systeme integriert oder für tiefere Analysen genutzt werden. Diese Tools eliminieren die Notwendigkeit manueller Tätigkeiten wie Dateneingabe, Validierung und Klassifizierung und ermöglichen es Ihrem Team, sich auf wertschöpfende Aufgaben zu konzentrieren, die Fachwissen und menschliches Urteilsvermögen erfordern.
In diesem umfassenden Leitfaden erklären wir Ihnen alles, was Sie über die Dokumentdatenextraktion wissen müssen. Von den Grundlagen der Technologie über ihre Funktionsweise bis hin zu den zahlreichen Vorteilen – wir decken alle wichtigen Aspekte ab. Nach der Lektüre werden Sie verstehen, warum KI-gestützte Lösungen zur Dokumentdatenextraktion für jedes Unternehmen, das seinen Workflow optimieren und wettbewerbsfähig bleiben möchte, unverzichtbar sind.
Dokumentdatenextraktion verstehen: Die Grundlagen

Bildnachweis: storyset
Was ist Dokumentdatenextraktion?
Unter Dokumentdatenextraktion versteht man den Prozess, relevante Informationen aus verschiedenen Arten von Dokumenten wie Verkaufsaufträgen, Rechnungen, Bestellungen und Quittungen zu extrahieren. Diese Daten können sowohl digital (z. B. PDFs, Word-Dateien) als auch physisch (z. B. Papierquittungen, handgeschriebene Formulare) vorliegen. Ziel der Dokumentdatenextraktion ist es, unstrukturierte oder Rohdaten in ein strukturiertes, maschinenlesbares Format umzuwandeln, das für weitere Verarbeitungsschritte oder Analysen in Systeme wie CRM- oder ERP-Lösungen integriert werden kann.
Wie funktioniert die Dokumentdatenextraktion? Der Prozess beginnt mit der Erfassung des Dokuments, unabhängig davon, ob es sich um ein physisches oder ein digitales Dokument handelt. Bei physischen Dokumenten wird zunächst ein Scan oder ein Bild erstellt, das mithilfe der optischen Zeichenerkennung (OCR) in Text umgewandelt wird. Anschließend kommen fortschrittliche Algorithmen und maschinelle Lernverfahren zum Einsatz, um relevante Datenpunkte wie Rechnungsnummern, Daten oder Preise zu identifizieren und zu extrahieren. Nach der Extraktion durchlaufen die Daten einen Validierungsprozess, um ihre Genauigkeit und Vollständigkeit sicherzustellen. Diese Validierung kann durch Abgleich mit vorhandenen Datensätzen oder anhand vordefinierter Regeln erfolgen. Zum Abschluss werden die validierten Daten in ein strukturiertes Format wie CSV oder XML umgewandelt und nahtlos in das gewünschte Zielsystem integriert.
Dieser mehrstufige Prozess kombiniert moderne Technologien mit optionalem menschlichem Eingreifen, um eine präzise, effiziente und zuverlässige Datenextraktion zu gewährleisten.
Arten von Dokumenten für die Datenextraktion
Ein typisches Unternehmen verarbeitet täglich eine Vielzahl von unstrukturierten Dokumenten, die Datenextraktion erfordern. Die häufigsten Dokumentarten und ihre relevanten Datenpunkte sind:

- Rechnungen: Rechnungen sind Handelsdokumente, die verwendet werden, um von einem Kunden die Zahlung für bereitgestellte Waren oder Dienstleistungen zu verlangen. Zu den wesentlichen Datenpunkten gehören Rechnungsnummer, Datum, Kunden- und Verkäuferinformationen, Beschreibung der Waren oder Dienstleistungen sowie das Fälligkeitsdatum der Zahlung.
- Verkaufs- und Einkaufsaufträge: Diese Dokumente erfassen und bestätigen den Verkauf von Waren oder Dienstleistungen zwischen Käufer und Verkäufer. Zu den extrahierten Informationen zählen Auftrags- und Bestellnummern, Artikelmengen, Preise, Liefertermine, Kunden- oder Lieferantendaten und Zahlungsbedingungen.
- Rechtsdokumente: Zu den gängigen Rechtsdokumenten gehören Verträge, Service-Level-Vereinbarungen (SLA), Lizenzvereinbarungen und Geheimhaltungsvereinbarungen (NDA). Extrahiert werden unter anderem die Namen der beteiligten Parteien, Vertragsdaten, Geschäftsbedingungen, Verpflichtungen und Rechte sowie Zahlungsdetails.
- Bank- und Finanzdokumente: Diese umfassen Kontoauszüge, Kreditkartenabrechnungen, Darlehensverträge und Kontoeröffnungsanträge. Wichtige Datenpunkte sind Transaktionsdetails, Darlehensbedingungen, Kontonummern, Zinssätze und Kundendaten.
- Versand- und Logistikdokumente: Zu diesen Dokumenten zählen Frachtbriefe, Packlisten, Rechnungen, Lieferbelege und Zollerklärungen. Relevante Informationen umfassen Versand- und Lieferdetails, Produktbeschreibungen, Mengen und Transportkosten.
Methoden zur Datenextraktion aus Dokumenten
Es gibt zwei Hauptmethoden, um Daten aus Dokumenten zu extrahieren: die manuelle Datenextraktion und die automatische Datenextraktion. Im Folgenden wird die manuelle Methode näher erläutert:
Manuelle Datenextraktion aus Dokumenten

Bildnachweis: Freepik
Vor der Einführung automatisierter Technologien war die manuelle Datenextraktion der Standardansatz, den Unternehmen für die Verarbeitung von Dokumentendaten nutzten. Diese Methode bietet zwar ein gewisses Maß an Kontrolle und Flexibilität, ist jedoch extrem zeitaufwendig, arbeitsintensiv und stark anfällig für Fehler.
Es gibt zwei Methoden, um Daten manuell aus Dokumenten zu extrahieren:
1. Manuelle Dateneingabe:
Bei dieser Methode werden Daten von einer Person direkt aus Dokumenten in ein digitales System eingegeben. Dabei liest die Person das Dokument, identifiziert relevante Datenpunkte und trägt diese manuell in ein System ein. Laut einer Studie von Plutoshift verwenden 48 % der Fertigungsunternehmen immer noch manuelle Methoden wie Tabellenkalkulationen, um Daten zu sammeln und zu analysieren. Dieselbe Studie zeigt, dass 37 % der Befragten kein Vertrauen in die Genauigkeit ihrer Daten haben, da manuelle Eingabefehler wie Tippfehler oder falsche Dateneingaben zu Unstimmigkeiten führen. Diese Fehler beeinträchtigen die Datenqualität und können schlechte Geschäftsentscheidungen nach sich ziehen.
2. Kopieren und Einfügen:
Hierbei werden Daten aus einem Dokument kopiert und in ein digitales System oder Format eingefügt. Obwohl diese Methode schneller als die manuelle Dateneingabe ist, birgt sie ähnliche Risiken menschlicher Fehler. Das ständige Kopieren und Einfügen erfordert keine Kreativität oder strategisches Denken, sondern lediglich monotone Wiederholung. Dadurch wird diese Aufgabe schnell langweilig und führt zu sinkender Produktivität. Außerdem ist sie nicht skalierbar: Je mehr Dokumente verarbeitet werden müssen, desto höher sind der Arbeitsaufwand und die benötigte Zeit für die Extraktion.
Einschränkungen und Herausforderungen der manuellen Datenextraktion aus Dokumenten

Bildnachweis: Freepik
Die manuelle Datenextraktion aus Dokumenten ist nicht nur fehleranfällig und zeitaufwendig, sondern weist auch mehrere andere Einschränkungen auf, die sie für Unternehmen, die ihre Datenextraktionsprozesse optimieren möchten, ungeeignet machen. Zu den wichtigsten Herausforderungen der manuellen Datenextraktion aus Dokumenten gehören:

- Begrenzte Skalierbarkeit: Manuelle Methoden der Datenextraktion sind nicht skalierbar. Der Grund? Nun, mit zunehmendem Dokumentenvolumen steigt auch der Zeit- und Arbeitsaufwand für die Datenextraktion. Dies macht es für Unternehmen schwierig, große Dokumentenmengen zeitnah und effizient zu verarbeiten.
- Subjektivität und Inkonsistenz: Die manuelle Datenextraktion ist stark von menschlichen Bedienern abhängig. Infolgedessen können verschiedene Personen unterschiedliche Interpretationen und Beurteilungen bei der Datenextraktion aus Dokumenten haben. Dies kann zu Unstimmigkeiten und Ungenauigkeiten in den extrahierten Daten führen, wodurch sie für die Entscheidungsfindung unzuverlässig werden.
- Hohe Betriebskosten: Die manuelle Extraktion von Daten aus Dokumenten erfordert erhebliche personelle Ressourcen, was für Unternehmen hohe Arbeitskosten bedeutet. Darüber hinaus erfordert die manuelle Datenextraktion oft erfahrenes und qualifiziertes Personal mit Fachkenntnissen, was die Betriebskosten weiter erhöht.
- Geringere Produktivität und Arbeitsmoral: Die manuelle Datenextraktion ist eine monotone und mühsame Aufgabe. Die sich wiederholende Natur dieser Arbeit kann zu Langeweile, Müdigkeit und mangelnder Produktivität bei den Mitarbeitern führen. Dies wiederum kann sich negativ auf ihre Arbeitsmoral und -zufriedenheit auswirken. Und nicht nur die Mitarbeiter leiden darunter, auch Unternehmen tragen die Hauptlast der geringeren Produktivität und Mitarbeiterzufriedenheit, was sich letztlich auf ihr Geschäftsergebnis auswirken kann.
Technologien zur automatisierten Datenextraktion aus Dokumenten

Bildnachweis: macrovector_official
Automatisierte Lösungen nutzen innovative Technologien wie KI und maschinelles Lernen (ML) sowie klassische Tools wie optische Zeichenerkennung (OCR), um Daten effizient und präzise zu extrahieren. Diese Technologien ermöglichen es Unternehmen, ihre Prozesse zu optimieren und dabei Zeit und Kosten zu sparen.
Automatisierte Lösungen zur Dokumentdatenextraktion nutzen innovative Technologien wie maschinelles Lernen (ML) und künstliche Intelligenz (KI) oder eher klassische Lösungen wie optische Zeichenerkennung (OCR), um Daten effizient und präzise zu extrahieren. Diese Technologien ermöglichen es Unternehmen, ihre Prozesse zu optimieren und dabei Zeit und Kosten zu sparen.
Hier ist ein kurzer Überblick über einige der häufig verwendeten Technologien zur automatisierten Dokumentdatenextraktion:
Optische Zeichenerkennung (OCR)
OCR-Technologie wird eingesetzt, um Text aus gescannten Dokumenten, PDFs und Bildern zu extrahieren. Sie eignet sich hervorragend zur Digitalisierung und einfachen Datenextraktion, hat jedoch Schwierigkeiten bei komplexen Layouts oder der Interpretation des Textkontexts. Klassische OCR-Lösungen erfordern oft manuelle Anpassungen bei Layoutänderungen. Weiterentwicklungen wie die intelligente Zeichenerkennung (ICR) ermöglichen eine präzisere Verarbeitung, einschließlich der Erkennung handgeschriebener Texte.
KI-gesteuerte Technologien
Zusätzlich zu OCR und ICR setzen Unternehmen auf KI-basierte Techniken, die nicht nur Daten extrahieren, sondern auch den Kontext und die Semantik des Textes verstehen, was die Genauigkeit und Effizienz der Datenextraktion erhöht. Zu den häufigsten KI-Technologien zählen:

1. Maschinelles Lernen
Maschinelles Lernen (ML) nutzt Algorithmen, die darauf trainiert werden, aus Daten zu lernen und Muster zu erkennen. Diese Algorithmen extrahieren relevante Informationen aus Dokumenten und verbessern ihre Genauigkeit kontinuierlich. Ein spezieller Ansatz im ML ist die vorlagenbasierte Datenextraktion, bei der vordefinierte Vorlagen für spezifische Informationen verwendet werden.
2. Verarbeitung natürlicher Sprache (NLP)
NLP ermöglicht es Computern, menschliche Sprache zu verstehen und zu analysieren. Diese Technologie wird verwendet, um große Mengen an unstrukturierten Daten in natürlicher Sprache zu verarbeiten, wie z. B. Textklassifizierungen oder die Extraktion relevanter Inhalte.
3. Lösungen zur intelligenten Dokumentenverarbeitung (IDP)
IDP-Lösungen kombinieren Technologien wie OCR, NLP und ML, um die Dokumentdatenextraktion umfassend zu automatisieren. Sie interpretieren Dokumente, extrahieren relevante Informationen und lernen aus menschlichem Feedback, um ihre Leistung zu verbessern.
4. Große Sprachmodelle (LLMs)
LLMs sind fortschrittliche KI-Systeme, die auf riesigen Textdatenmengen trainiert werden. Diese Modelle verstehen menschliche Sprache, interpretieren Texte und extrahieren selbst aus unstrukturierten oder handschriftlichen Dokumenten Daten. Durch kontinuierliches Selbstlernen verbessern sie ihre Genauigkeit und Effizienz im Laufe der Zeit.
Wie funktioniert die automatisierte Dokumentdatenextraktion?
Der Prozess der automatisierten Dokumentdatenextraktion kombiniert verschiedene Tools, Techniken und Algorithmen, um Informationen aus komplexen Dokumenten effizient und mit minimalem menschlichem Eingriff zu extrahieren. Nachfolgend sind die wesentlichen Schritte aufgeführt, die in diesem Prozess durchlaufen werden:

1. Dokumenteneingang und Vorverarbeitung
Der erste Schritt umfasst das Sammeln und Vorbereiten der Dokumente. Hierzu zählen Aufgaben wie Bildverbesserung und Rauschunterdrückung, um die Dokumentenqualität zu optimieren und eine präzise Datenextraktion zu ermöglichen.
2. Konvertierung gescannter Bilder in Text
Im nächsten Schritt werden gescannte Dokumente oder PDFs mithilfe von OCR-Technologie (Optical Character Recognition) in durchsuchbaren und bearbeitbaren Text umgewandelt. Diese Technologie ermöglicht es, Daten aus nicht-digitalen Quellen wie Papierunterlagen oder handschriftlichen Formularen zu extrahieren.
3. Erkennung von Datenpunkten
In diesem Schritt werden die spezifischen Datenpunkte oder Felder definiert und identifiziert, die aus dem Dokument extrahiert werden sollen. Bei einer Rechnung könnten diese beispielsweise den Kundennamen, die Bestellnummer oder den fälligen Gesamtbetrag umfassen. Hierbei wird die Struktur des Dokuments analysiert, um die relevanten Informationen zu lokalisieren.
4. Datenextraktion
Sobald die benötigten Datenpunkte identifiziert sind, kommen verschiedene Extraktionstechniken wie Musterabgleich, regelbasierte Methoden und Datenanalyse zum Einsatz. Beim Musterabgleich werden spezifische Formate oder Muster erkannt, um die gewünschten Daten zu extrahieren. Die Datenanalyse hingegen untersucht die Struktur des Dokuments, um die relevanten Informationen präzise herauszufiltern.
5. Datenvalidierung und -verifizierung
Nach der Extraktion durchlaufen die Daten einen Validierungsprozess, um ihre Genauigkeit und Konsistenz sicherzustellen. Dies erfolgt durch den Vergleich mit vordefinierten Regeln oder Datenqualitätsprüfungen. Sollten Unstimmigkeiten, wie fehlende oder fehlerhafte Daten, erkannt werden, kennzeichnet das System diese zur manuellen Überprüfung und Korrektur.
Bewährte Verfahren zur Optimierung des Prozesses der Dokumentdatenextraktion
Wenn Sie die Effizienz und Genauigkeit bei der Dokumentdatenextraktion maximieren möchten, gibt es einige bewährte Ansätze, die Sie berücksichtigen sollten:
- Verwenden Sie qualitativ hochwertige Scans oder Bilder: Um bessere OCR-Ergebnisse zu erzielen und die Genauigkeit der Datenextraktion zu erhöhen, sollten Sie sicherstellen, dass die Dokumente in bestmöglicher Qualität gescannt oder fotografiert werden. Hochwertige Vorlagen reduzieren Fehler und erhöhen die Effizienz.
- Regelmäßige Aktualisierung von Modellen für maschinelles Lernen: ML-Modelle sollten kontinuierlich mit neuen Datensätzen trainiert und aktualisiert werden. Dies ermöglicht es den Algorithmen, sich an geänderte Dokumentenlayouts oder -formate anzupassen und so die Extraktionsleistung stetig zu verbessern.
- Hybride Datenextraktionsansätze nutzen: Kombinieren Sie verschiedene Methoden, um eine höhere Genauigkeit zu erreichen. Regelbasierte Extraktionsmethoden eignen sich für strukturierte und vorhersehbare Daten, während maschinelles Lernen oder LLMs besser mit unstrukturierten oder komplexen Daten umgehen können.
- Datenvalidierungsmechanismen integrieren: Eine robuste Datenvalidierung stellt sicher, dass die extrahierten Informationen fehlerfrei und konsistent sind. Dadurch werden Unstimmigkeiten identifiziert und korrigiert, bevor die Daten in weiterführenden Prozessen verwendet werden.
- Skalierbarkeit sicherstellen: Entwerfen Sie den Prozess so, dass er auch bei großen Dokumentenvolumen reibungslos funktioniert, ohne Unterbrechungen oder Leistungseinbußen.
Neben der automatischen Extraktion relevanter Informationen bieten KI-gestützte Lösungen zur Dokumentdatenextraktion zahlreiche weitere Vorteile. Dazu zählen unter anderem eine verbesserte Datensicherheit, schnellere Durchlaufzeiten und eine höhere Transparenz. Dank der geringen Fehlerquote und der beschleunigten Verarbeitung können Unternehmen die Kundenzufriedenheit steigern.
Moderne KI-Software lässt sich zudem nahtlos in bestehende Systeme wie CRM- oder ERP-Lösungen integrieren. Dies sorgt für einen reibungslosen Datentransfer und optimiert Geschäftsprozesse. Darüber hinaus ermöglichen KI-Lösungen prädiktive Analysen, die zukünftige Trends basierend auf den extrahierten Daten vorhersagen. Beispielsweise können Algorithmen Muster in den Zahlungsgewohnheiten eines Kunden erkennen und die Wahrscheinlichkeit zukünftiger verspäteter Zahlungen prognostizieren. So können Unternehmen Risiken frühzeitig identifizieren und effektiver managen.
Manuelle Dokumentdatenextraktion vs. KI-automatisierte Dokumentdatenextraktion: Was ist besser?
Vergleichen wir die manuelle Dokumentdatenextraktion und die KI-automatisierte Extraktion, um herauszufinden, welche Methode besser zu den Anforderungen Ihrer Organisation passt:

Wie turian Ihnen helfen kann, Ihren Prozess zur Datenextraktion aus Dokumenten zu optimieren
Wenn Sie nach einer umfassenden, KI-gesteuerten Lösung suchen, um die Herausforderungen manueller Datenextraktion zu überwinden, ist turian die ideale Wahl. Mit fortschrittlicher KI-Technologie, darunter große Sprachmodelle (LLMs), proprietären Sicherheitsschichten und anpassbaren Geschäftsregeln, automatisiert turian die Dokumentdatenextraktion mit höchster Geschwindigkeit und Präzision. turian kann Daten aus unterschiedlichsten Dokumenten wie E-Mails, PDFs, Word-Dateien, Excel-Tabellen und sogar Bildern extrahieren – unabhängig davon, ob die Daten halbstrukturiert oder völlig unstrukturiert sind. Die LLMs von turian sind flexibel genug, um alle Anforderungen zu bewältigen.
Neben der Extraktion validiert und verifiziert turian die Daten, um Genauigkeit und Vollständigkeit zu gewährleisten. Fehlt beispielsweise ein Wert im Quelldokument oder ist dieser fehlerhaft, erkennt turian das Problem und markiert es zur Überprüfung. So sparen Sie wertvolle Zeit, die sonst für manuelle Datenvalidierung aufgewendet würde. Von der Datenanalyse bis hin zur Klassifizierung von Dokumenten bietet turian eine vollständige End-to-End-Lösung, die Ihren gesamten Dokumentenworkflow optimiert.
Aber turian kann mehr als nur Daten extrahieren. Dank seiner Verarbeitung natürlicher Sprache (NLP) kann es auch komplexe Aufgaben wie das Verfassen von E-Mails oder die Analyse von Kundenfeedback übernehmen. Durch den Einsatz von LLMs versteht turian den Kontext und die Nuancen der Daten und liefert präzise Ergebnisse – fast so, als würde ein Mensch die Aufgabe ausführen.
Ein weiterer Vorteil von turian ist seine nahtlose Integration in bestehende ERP- und CRM-Systeme sowie in E-Mail-Clients wie Outlook und Gmail. Das bedeutet, dass Sie Ihre Arbeitsabläufe nicht unterbrechen oder zwischen verschiedenen Plattformen wechseln müssen – alle Ihre Dokumente und Daten sind zentral zugänglich.
Die Implementierung von turian ist unkompliziert. Als Plug-and-Play-Lösung ist es innerhalb weniger Tage einsatzbereit und erfordert keinen Programmieraufwand. Anders als herkömmliche maschinelle Lernsysteme oder Technologien wie OCR benötigt turian keine umfangreichen Trainingsdaten oder manuelle Anpassungen für unterschiedliche Dokumenttypen. Es ist eine hochgradig anpassbare Lösung, die sich nahtlos an Ihre spezifischen Geschäftsprozesse und Branchenanforderungen anpasst.
Um Sie von seinen Fähigkeiten zu überzeugen, bietet turian einen kostenlosen und unverbindlichen Proof of Concept (PoC) an. Mit dieser Demo können Sie firsthand erleben, wie turian Ihre Dokumentdatenextraktionsprozesse optimiert und Ihre Geschäftsabläufe transformiert.
Effiziente Dokumentdatenextraktion ist der Schlüssel zu besseren Entscheidungen, optimiertem Kundenservice und einem Wettbewerbsvorteil. Mit turian erhalten Sie nicht nur eine Automatisierungslösung, sondern eine vollständige Transformation Ihres Dokumentenmanagements, sodass Ihr Team sich auf strategische Kerntätigkeiten konzentrieren kann – ganz ohne den Aufwand manueller Datenextraktion.
{{de-cta-block-blog}}

Say hi to your
AI Assistant!
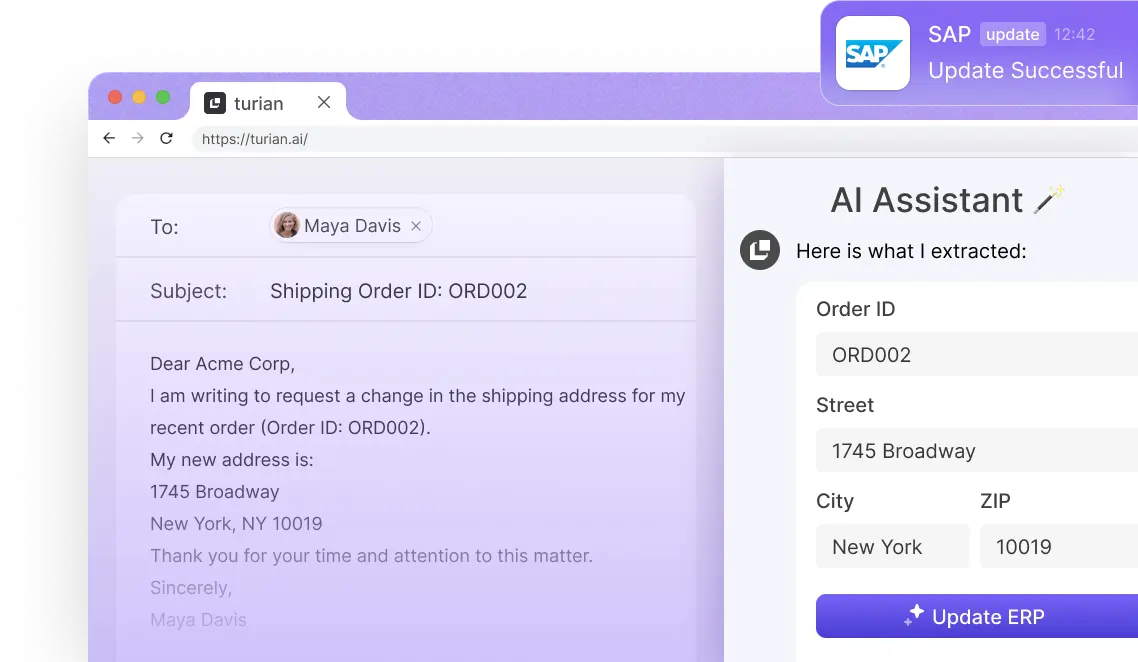
Lernen Sie Ihren KI-Assistenten kennen!
.avif)
FAQ
Lösungen zur Dokumentdatenextraktion basieren auf Technologien wie natürlicher Sprachverarbeitung (NLP), künstlicher Intelligenz (KI), maschinellem Lernen (ML), optischer Zeichenerkennung (OCR) und intelligenter Zeichenerkennung (ICR). Diese Technologien ermöglichen es, Daten zu strukturieren, Dokumente zu klassifizieren, relevante Informationen zu identifizieren und diese in einem strukturierten Format für weitere Verarbeitung oder Analysen bereitzustellen.
Die Automatisierung von Dokumentdatenextraktionsprozessen durch KI-gestützte Lösungen spart Zeit und Aufwand, indem manuelle Schritte wie Datenextraktion, Klassifizierung, Validierung und Eingabe entfallen. Dadurch wird nicht nur die betriebliche Effizienz gesteigert, sondern auch menschliche Fehler reduziert und die Datengenauigkeit verbessert. Zudem können Unternehmen durch die Automatisierung größere Dokumentenmengen in kürzerer Zeit bearbeiten und ihre Abläufe skalieren, ohne zusätzliche Ressourcen zu benötigen.
Die Genauigkeit von Lösungen zur Dokumentdatenextraktion variiert je nach eingesetzter Technologie. KI-automatisierte Lösungen wie turian erreichen jedoch eine Genauigkeit von bis zu 99 %, je nach Aufgabe. Das ist deutlich höher als bei manuellen Dateneingabemethoden, deren Fehlerquote üblicherweise zwischen 1 % und 10 % liegt.
turian kann Daten aus einer Vielzahl von unstrukturierten Dokumenten wie E-Mail-Texten, Word-Dateien, PDFs, Excel-Tabellen und sogar Bildern extrahieren. Dank der Verwendung großer Sprachmodelle (LLMs) ist turian in der Lage, mit unstrukturierten und unordentlichen Daten umzugehen und relevante Informationen für die Weiterverarbeitung zu extrahieren. Darüber hinaus nutzt turian natürliche Sprachverarbeitung (NLP), wodurch es Kontext und Bedeutung hinter dem Text verstehen und Daten präzise aus unterschiedlichen Dokumententypen extrahieren kann.



